Virtual column is an integral table engine attribute that is defined in the engine source code.
You shouldn’t specify virtual columns in the CREATE TABLE query and you can’t see them in SHOW CREATE TABLE and DESCRIBE TABLE query results. Virtual columns are also read-only, so you can’t insert data into virtual columns.
To select data from a virtual column, you must specify its name in the SELECT query. SELECT * does not return values from virtual columns.
If you create a table with a column that has the same name as one of the table virtual columns, the virtual column becomes inaccessible. We do not recommend doing this. To help avoid conflicts, virtual column names are usually prefixed with an underscore.
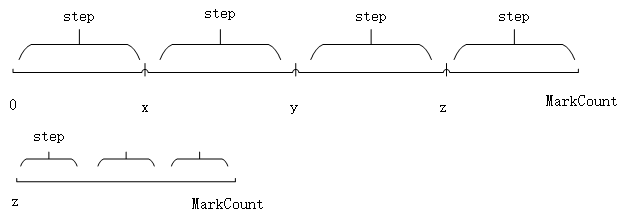
virtual columns的常用值如下
1 2 3 4 5 6
_part -- name of a part _part_index -- sequential index of the part in the query result _partition_id -- name of a partition _part_uuid -- unique part identifier, if enabled `MergeTree` setting `assign_part_uuids` (Part movement between shards) _partition_value -- values (tuple) of a `partition by` expression _sample_factor -- sample_factor from the query
MarkRanges MergeTreeDataSelectExecutor::markRangesFromPKRange( const MergeTreeData::DataPartPtr & part, const StorageMetadataPtr & metadata_snapshot, const KeyCondition & key_condition, const Settings & settings, Poco::Logger * log) { MarkRanges res; .... auto may_be_true_in_range = [&](MarkRange & range) //(1) { if (range.end == marks_count && !has_final_mark) { for (size_t i = 0; i < used_key_size; ++i) { create_field_ref(range.begin, i, index_left[i]); index_right[i] = POSITIVE_INFINITY; } } else { if (has_final_mark && range.end == marks_count) range.end -= 1; /// Remove final empty mark. It's useful only for primary key condition.
for (size_t i = 0; i < used_key_size; ++i) { create_field_ref(range.begin, i, index_left[i]); create_field_ref(range.end, i, index_right[i]); } } return key_condition.mayBeTrueInRange( used_key_size, index_left.data(), index_right.data(), primary_key.data_types); };
if (!key_condition.matchesExactContinuousRange()) {
while (!ranges_stack.empty()) //(2) { MarkRange range = ranges_stack.back(); ranges_stack.pop_back();
if (!may_be_true_in_range(range)) //(3) continue;
if (range.end == range.begin + 1) { /// We saw a useful gap between neighboring marks. Either add it to the last range, or start a new range. if (res.empty() || range.begin - res.back().end > min_marks_for_seek) //(4) res.push_back(range); else res.back().end = range.end; } else { /// Break the segment and put the result on the stack from right to left. size_t step = (range.end - range.begin - 1) / settings.merge_tree_coarse_index_granularity + 1; size_t end;
for (end = range.end; end > range.begin + step; end -= step) ranges_stack.emplace_back(end - step, end);
for (size_t i = 0; i < parts.size(); ++i) { PartInfo part_info{parts[i], per_part_sum_marks[i], i}; if (parts[i].data_part->isStoredOnDisk()) parts_per_disk[parts[i].data_part->volume->getDisk()->getName()].push_back(std::move(part_info)); else parts_per_disk[""].push_back(std::move(part_info)); }
for (auto & info : parts_per_disk) parts_queue.push(std::move(info.second)); }
// 遍历每一个线程,为每一个线程分配任务 for (size_t i = 0; i < threads && !parts_queue.empty(); ++i) { auto need_marks = min_marks_per_thread;
while (need_marks > 0 && !parts_queue.empty()) { auto & current_parts = parts_queue.front(); RangesInDataPart & part = current_parts.back().part; size_t & marks_in_part = current_parts.back().sum_marks; const auto part_idx = current_parts.back().part_idx;
/// Do not get too few rows from part. if (marks_in_part >= min_marks_for_concurrent_read && need_marks < min_marks_for_concurrent_read) need_marks = min_marks_for_concurrent_read;
/// Do not leave too few rows in part for next time. if (marks_in_part > need_marks && marks_in_part - need_marks < min_marks_for_concurrent_read) need_marks = marks_in_part;
/// Get whole part to read if it is small enough. if (marks_in_part <= need_marks) { ranges_to_get_from_part = part.ranges; marks_in_ranges = marks_in_part;
need_marks -= marks_in_part; current_parts.pop_back(); if (current_parts.empty()) parts_queue.pop(); } else { /// Loop through part ranges. while (need_marks > 0) { if (part.ranges.empty()) throw Exception("Unexpected end of ranges while spreading marks among threads", ErrorCodes::LOGICAL_ERROR);
... /// Do not leave too little rows in part for next time. // 如果此次获取到的range后,剩下的mark比较少,那么就一次行读整个DataPart,提高效率。 if (marks_in_part > need_marks && marks_in_part - need_marks < min_marks_to_read) need_marks = marks_in_part;
MarkRanges ranges_to_get_from_part;
/// Get whole part to read if it is small enough. //DataPart本身含有的mark总数就比较少,也一次性的读取整个DataPart if (marks_in_part <= need_marks) { const auto marks_to_get_from_range = marks_in_part; ranges_to_get_from_part = thread_task.ranges;
if (thread_tasks.sum_marks_in_parts.empty()) remaining_thread_tasks.erase(thread_idx); } else {
/// Loop through part ranges. // 遍历这个DataPart的range,找到足够数量的mark然后返回。 while (need_marks > 0 && !thread_task.ranges.empty()) { auto & range = thread_task.ranges.front();