RDD
RDD是一个只读的分区的数据集合,可以通过两种方式来生成
- data in stable storage,例如HDFS
- other RDDs,通过对已经存在的RDD经过transformations操作,比如map,filter,join等。
需要注意的是,RDD中不一定含有物理数据,RDD只是包含了一些信息,利用这些信息我们可以从reliable storage中的数据重新计算这个RDD。
RDD的实现
每个RDD对象实现了同一个接口,接口中含有下列操作(接口名字只是示意功能,具体spark实现的接口名字并不一定如此)
1 | getPations 返回RDD所有partion的ID |
比如HDFSTextFile,getPations方法返回的是其数据对应的HDFS的块ID(隐含着每个partion对应一个HDFS block),getIterator 返回一个数据流来读这个block。再如MappedDataSet的partitions和preferred locations跟他的parent RDD是相同的,但是他的iterator会将map function应用到parent RDD的每一个元素。
依赖的表达
依赖分为两种,narrow dependency和wide dependency,如下图所示。窄依赖指,子RDD的每个partition仅仅依赖父RDD的一个partition,简而言之,父RDD的partition和子RDD的partition存在一一对应的关系。比如常见的map和filter操作。宽依赖指父RDD的每个patrition可能被子RDD的多个partition使用。形象的可以说,从父RDD角度来看,父RDD指向子RDD的箭头为一个则为窄,多个则为宽。
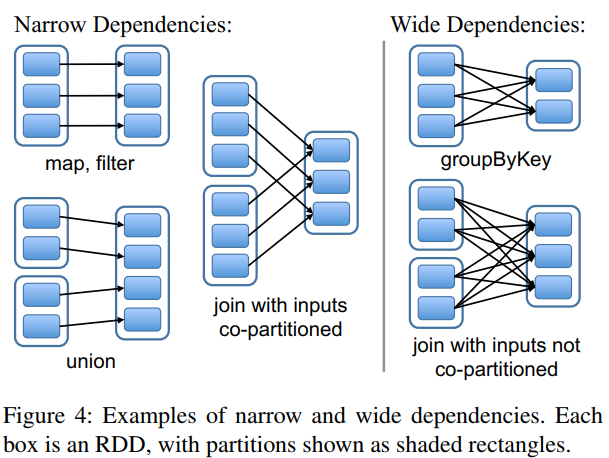
RDD操作
RDD操作分为transformations和actins,transformation从一个已经存在的RDD生成一个新的RDD。Actions会触发在RDD上的计算并处理返回的结果,例如返回给用户或者保存到到持久存储。
Action是immediate effect的,而transform是lazy的,意思是spark程序中只有遇到action才会执行之前定义的一系列tranform进行实际的计算。一般的RDD操作如果返回的是一个新RDD,那么是一个transformation操作,否则是一个action。总结如下,图来自[1]。

Shared Variables
Spark程序可能经常会需要获取非RDD数据,比如Hadoop权威指南[3]中的例子,如下所示
1 | val lookup = Map(1 -> "a", 2 -> "e", 3 -> "i", 4 -> "o", 5 -> "u") |
虽然工作正常,但是这样lookup的数据会被scala程序序列化成closure的一部分,没有效率。
Broadcast Variables
broadcast variable会被序列化然后发送到每个executor(可以理解为worker节点)中去,然后会被cache,所以在这个executror中执行的task都可以直接获取他。而像上述所说的普通变量序列化为闭包的一部分,则每个task都需要通过网络传输一次这个变量数据。Broadcast variable不可改变。如果需要改变则需要Accumulators。
Accumulators
一个Accumulators是一个共享变量,但是只能故名思议只能累加,类似于Map-Reduce中的counters。
Spark job run
spark的job调度分为两个层面,一个是DAG scheduler将linage graph划分为stages,
在每个stages,又有task scheduler根据每个execturor的情况进行task的调度,基本原则就是data locality。这里主要讲下DAG Scheduler划分stage的原则。
上述讲过RDD的依赖有窄依赖和宽依赖,对于窄依赖而言,可以每个partition分配一个task来进行计算并将结过输出到一系列新的分区中,此过程类似于Map-Reduce中的Map side,因此这样的task被称为Shuffle map tasks。而宽依赖因为依赖父RDD多个分区,在进行下一步的计算之前需要一个shuffle过程。而这个shuffle过程就成为了分割stage的分割线。如下图所示。

分为三个stage,stage1和stage2均是窄依赖,而join操作是宽依赖,因此在进行join操作之前需要一个shuffle过程。至于为什么要划分stages,个人可能是每个stage中都是窄依赖,可能有利于
流水线的执行和优化。
参考文献
[1]Zaharia, Matei, et al. “Resilient Distributed Datasets: A {Fault-Tolerant} Abstraction for {In-Memory} Cluster Computing.” 9th USENIX Symposium on Networked Systems Design and Implementation (NSDI 12). 2012.
[2]Zaharia, Matei, et al. “Spark: Cluster computing with working sets.” 2nd USENIX Workshop on Hot Topics in Cloud Computing (HotCloud 10). 2010.
[3]White, Tom. “Hadoop-The Definitive Guide: Storage and Analysis at Internet Scale. 4th.” (2015).
[4]https://www.studytime.xin/article/spark-knowledge-rdd-stage.html