Hadoop
Hadoop Map-Reduce模型
Hadoop的整体计算数据流如下图所示:MapReduce 编程模型将计算过程分为两个阶段 Map和Reduce,这两个阶段都接受key-value元组作为输入。用户一般通过指定map和reduce两个函数即可,其他的交给Hadoop框架。
Hadoop将整个输入分为固定大小的块(input split)来作为
每个Map任务的输入,也就是说针对每一个input split启动一个map task,而且常常split的大小与Hadoop分布式文件系统HDFS的block大小(128M)是相等的。这个是可以通过参数来配置的。split的大小一般设置为hdfs的block大小是因为,在大数据系统中,相对移动数据和移动程序,移动数据的开销比较大,因此通常会将map任务调度在拥有split的那个节点中运行(data locality),而如果split的大小多于1个block,不能保证节点中都拥有这两个文件block,那么这个map task
无论运行在哪个节点都需要跨节点传输数据。但是有时候因为如果这个节点因为运行了其他task,并不能满足data locality,则Hadoop会尽量将map调度在和数据在的那个节点同一个机架的另一个节点中来尽量较少数据传输的开销。
map task的输出仍然是key-value,但是reduce task的输入要求从每个map task 拷贝来得数据都是有序的,这一将map的输出转化为reduce task输入的过程称为shuffle。最终有reduce将结果写入到HDFS系统中,而map的输入作为中间结果则并不是直接写入到HDFS,而是写入本地磁盘(因为map task的输出是中间结果,最终整个job完成还是需要删除的。而且可能会失败,如果写入到hdfs,重新调度失败的task,不但任务要重做还要删除hdfs中的数据,hdfs中的block是有三副本的,因此写入开销比较大)。

具体的Map-Reduce过程如下图所示。map将输入split处理后的结果写入磁盘等待reduce task
来拷贝,这里注意的是如果有多个reducer,那么每个map task的输出需要进行partion和sort操作(具体过程见Shuffle and Sort)。partion可以理解为对map的输出中的key进行划分,确保同一个key被分到同一个partion,而每个partion可以拥有多个key。每个partion对应于一个reducer,等全部map task完成后,对应partion的reducer会来取对应partion的数据。每个partion中的所有数据时根据key排序好的。途中表示的为三个mapper和2个reducer因此,每个mapper的输出被分为两个partion。具体的sort和partion过程,以及数据的存放形式见Shuffle and Sort。
shuffle and Sort
1 | MapReduce makes the guarantee that the input to every reducer is sorted by key. |

map task中的输出结果首先写入到circular memory buffer,默认大小为100M,buffer的大小也可以通过参数配置。当buffer中内容达到了某个阙值,会有后台线程会将buffer中的数据写入到文件(本地磁盘),map 输出到buffer和buffer数据读出到文件时同时进行的,除非buffer中已经满了,那么map会阻塞直到后台程序将所有数据写入到文件。后台程序在将
buffer数据写入到文件之前会首先对数据进行partion,而且会对每个partion在内存中进行排序,如果定义了combiner则会执行combiner函数。每次buffer达到阙值之后,后台线程都会写入到一个新文件,所以当map task的输出写完后,会有多个split file。这个split file 是分区有序的,即在每个分区内,数据都是根据key排好序的。在map task完成之前,所有的spil files会被merge成一个分区有序文件。在合并期间可能还会执行combiner函数来减少写入磁盘的数据。如果spile file太少可能就不执行combiner函数(对每个split file执行combiner函数)了,因为考虑到执行combiner函数也有开销,文件太少不值得。
每个reducer需要跨节点来请求map task的输出。为了尽快完成数据拷贝,每当有一个map任务完成,reducer都会去获取数据(多线程)。map的任务完成后会通知application master(YARN中会讲到,applicatinn master是监控任务的执行情况),而每个reducer会有后台线程不断的去询问applicaton master是否有map完成并获取map输出文件位置。拷贝来的数据首先写入到
内存buffer,这个buffer大小可以设置,通常比较大,因为shuffle阶段,reduce无法进行。
当内存buffer中数据达到某个阙值(默认0.8)则类似于map阶段,溢出到文件。则最终也会在磁盘生成多个split file如下图所示。当磁盘中有多个split file,会有后台线程去merge这些文件。磁盘merge和内存merge是同时运行的(merge1和merge2)。最后一轮merge(merge3)通常是来自内存和磁盘,从而减少一次读写文件。最终生成一个最终的排序文件作为reduce的输入。
1 | This final merge can come from a mixture of in-memory and |

combiner
许多 MapReduce 作业受到集群上可用带宽的限制,因此尽量减少在 map 和 reduce 任务之间传输的数据是值得的。 Hadoop 允许用户指定要在map的输出上运行combiner函数,combiner函数的output 形成 reduce 函数的输入。 因为combiner函数是一种优化,所以 Hadoop 不保证它会为特定的map输出调用多少次。换句话说,调用combiner零次、一次或多次都不影响最终reducer的输出。
举个Hadoop权威指南的例子(年份,温度),map-reduce job为找到每年的最高温度。
第一个map产生输出(1950,0),(1950,20),(1950,10)
第二个map产生输出(1950,25),(1950,15)
如果没有combiner函数那么最终reducer的输入为((1950, [0, 20, 10, 25, 15]))
如果本例中combiner函数和reduce函数一样,那么reduceer 的输入为(1950, [20, 25]),
从而减少了map到reduce的数据拷贝。
YARN
Apache YARN(Yet Another Resource Negotiator),是一个资源管理系统。YARN在Hadoop2中被引入,因为在Hadoop1中的jobtracker背负了太多的任务,比如资源调度,task监控。引入YARN将部分任务分离出来。
Yarn的核心组件包括两个长久运行的守护进程,resource manager和node manager。 resource manager每个集群只有一个,node manager每个机器一个。
Container : 抽象的资源包括内存,cpu等。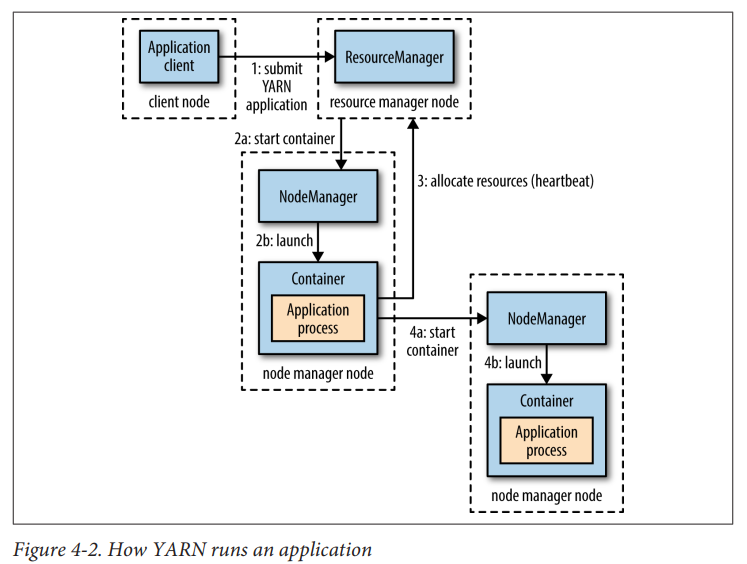
向yarn的请求资源的流程为上图所示。首先客户端向resource manager提交job(step1),资源管理器会首先联系某个NodeManager启动一个Cotainer来运行application master(step2a和step2b),application master运行的程序根据不同的上层应用而不同。如果本节点的container满足了程序的要求,那么无需申请更多container,否则该applicatin master会
向resource manager请求跟多container(step3),然后会联系其他的node manager进行分布式计算(step4a,step4b)。具体的以Hadoop提交map-reduce作业为例详细解释,如下图所示。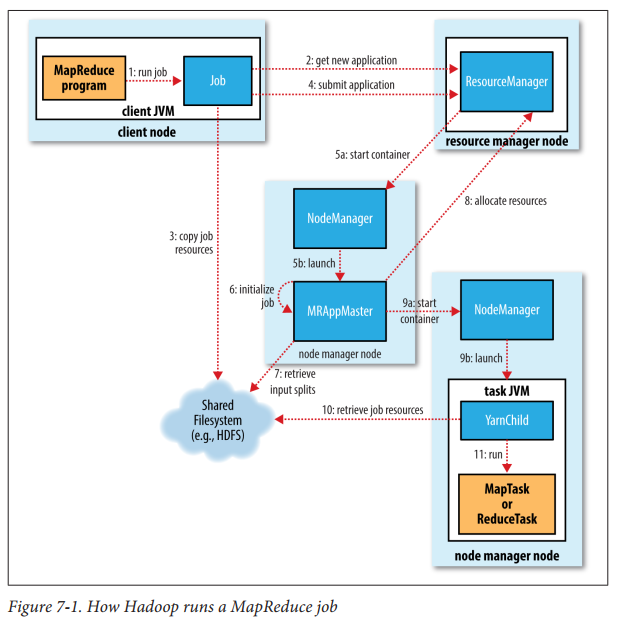
首先MapReduce程序会向resoure manager请求一个应用程序ID(step2),map-reduce客户端也会检查job的合法性,比如输入文件和输出文件是否存在,如果不合法(比如输入文件不存在,输出文件已经存在)则直接报错。注意job的input spile也是在这里计算的。最后需要将job所需要的资源比如job jar文件,配置文件,计算好的input spiles(应该只是一个划分信息,并不是真正的数据)等等信息拷贝打包发送给资源管理器来提交job(step4)
resource manager收到job后,其中调度器会处理这个请求然后分配一个container,resource manager会通知对应节点的node manager来这个container来运行MRAppMaster程序,该程序主要是监督job的完成情况,会创建一系列的bookkeeping 对象来维护跟踪job的进度。接着会创建获取input split,然后创建一系列的mao和reduce task对象。application master需要决定如何运行这个job,如果这个job比较小,那么applicaion master 会在自己的几点上运行整个job,否则application master 会向resource manager请求containers来运行这些map和reduce task(step8)。map请求优先级会高于reduce,因为只有全部的map task完成才会进入reduce task的sort阶段。在资源请求得到满足后,application master 会向对应的node mananger发送信息来启动container,这里的container执行的main class 为YarnChild,并由YarnChild来执行task,执行task之前。
YarnChild会获取执行这个task的相关资源(step10),最后运行map或者reduce task(step11)。
参考文献
[1] White, Tom. “Hadoop-The Definitive Guide: Storage and Analysis at Internet Scale. 4th.” (2015).
[2] https://andr-robot.github.io/Hadoop%E4%B8%ADShuffle%E8%BF%87%E7%A8%8B/