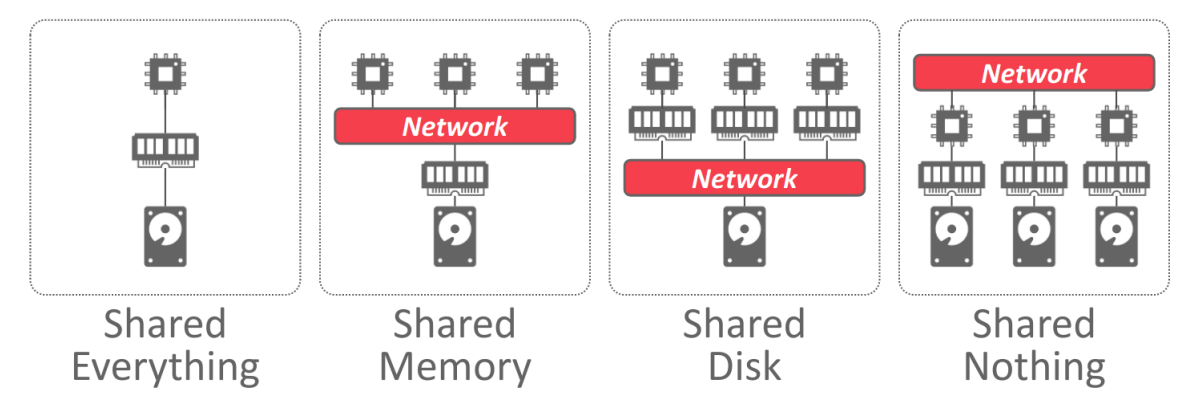
A DBMS’s system architecture specifies what shared resources are directly accessible to CPUs. It affects how CPUs coordinate with each other and where they retrieve and store objects in the database.
void MergeTreeSink::finishDelayedChunk() { if (!delayed_chunk) return;
for (auto & partition : delayed_chunk->partitions) { partition.temp_part.finalize(); //(1)
auto & part = partition.temp_part.part;
/// Part can be deduplicated, so increment counters and add to part log only if it's really added //(2) if (storage.renameTempPartAndAdd(part, context->getCurrentTransaction().get(), &storage.increment, nullptr, storage.getDeduplicationLog(), partition.block_dedup_token)) { PartLog::addNewPart(storage.getContext(), part, partition.elapsed_ns);
/// Initiate async merge - it will be done if it's good time for merge and if there are space in 'background_pool'. storage.background_operations_assignee.trigger(); //(3) } }
Executor for a background MergeTree related operations such as merges, mutations, fetches an so on. * It can execute only successors of ExecutableTask interface. * Which is a self-written coroutine. It suspends, when returns true from executeStep() method.
auto future_part = std::make_shared<FutureMergedMutatedPart>();
if (storage_settings.get()->assign_part_uuids) future_part->uuid = UUIDHelpers::generateV4();
auto can_merge = [this, &lock](const DataPartPtr & left, const DataPartPtr & right, const MergeTreeTransaction * tx, String *) -> bool { if (tx) { /// Cannot merge parts if some of them are not visible in current snapshot /// TODO Transactions: We can use simplified visibility rules (without CSN lookup) here if (left && !left->version.isVisible(tx->getSnapshot(), Tx::EmptyTID)) return false; if (right && !right->version.isVisible(tx->getSnapshot(), Tx::EmptyTID)) return false;
/// Do not try to merge parts that are locked for removal (merge will probably fail) if (left && left->version.isRemovalTIDLocked()) return false; if (right && right->version.isRemovalTIDLocked()) return false; }
/// This predicate is checked for the first part of each range. /// (left = nullptr, right = "first part of partition") if (!left) return !currently_merging_mutating_parts.count(right); return !currently_merging_mutating_parts.count(left) && !currently_merging_mutating_parts.count(right) && getCurrentMutationVersion(left, lock) == getCurrentMutationVersion(right, lock) && partsContainSameProjections(left, right); };
/// TTL requirements is much more strict than for regular merge, so /// if regular not possible, than merge with ttl is not also not /// possible. if (max_source_parts_size > 0) { select_decision = merger_mutator.selectPartsToMerge( future_part, aggressive, max_source_parts_size, can_merge, merge_with_ttl_allowed, txn, out_disable_reason); } else if (out_disable_reason) *out_disable_reason = "Current value of max_source_parts_size is zero"; } else { ... } ... merging_tagger = std::make_unique<CurrentlyMergingPartsTagger>(future_part, MergeTreeDataMergerMutator::estimateNeededDiskSpace(future_part->parts), *this, metadata_snapshot, false); return std::make_shared<MergeMutateSelectedEntry>(future_part, std::move(merging_tagger), MutationCommands::create()); }
MergeTreeDataPartInMemory::ColumnToSize local_merged_column_to_size; for (const MergeTreeData::DataPartPtr & part : global_ctx->future_part->parts) part->accumulateColumnSizes(local_merged_column_to_size);
void MergeTask::ExecuteAndFinalizeHorizontalPart::createMergedStream() { /** Read from all parts, merge and write into a new one. * In passing, we calculate expression for sorting. */ Pipes pipes;
... for (const auto & part : global_ctx->future_part->parts) { auto input = std::make_unique<MergeTreeSequentialSource>( *global_ctx->data, global_ctx->storage_snapshot, part, global_ctx->merging_column_names, ctx->read_with_direct_io, true);
Virtual column is an integral table engine attribute that is defined in the engine source code.
You shouldn’t specify virtual columns in the CREATE TABLE query and you can’t see them in SHOW CREATE TABLE and DESCRIBE TABLE query results. Virtual columns are also read-only, so you can’t insert data into virtual columns.
To select data from a virtual column, you must specify its name in the SELECT query. SELECT * does not return values from virtual columns.
If you create a table with a column that has the same name as one of the table virtual columns, the virtual column becomes inaccessible. We do not recommend doing this. To help avoid conflicts, virtual column names are usually prefixed with an underscore.
virtual columns的常用值如下
1 2 3 4 5 6
_part -- name of a part _part_index -- sequential index of the part in the query result _partition_id -- name of a partition _part_uuid -- unique part identifier, if enabled `MergeTree` setting `assign_part_uuids` (Part movement between shards) _partition_value -- values (tuple) of a `partition by` expression _sample_factor -- sample_factor from the query
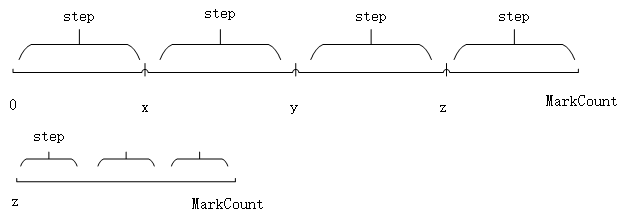
MarkRanges MergeTreeDataSelectExecutor::markRangesFromPKRange( const MergeTreeData::DataPartPtr & part, const StorageMetadataPtr & metadata_snapshot, const KeyCondition & key_condition, const Settings & settings, Poco::Logger * log) { MarkRanges res; .... auto may_be_true_in_range = [&](MarkRange & range) //(1) { if (range.end == marks_count && !has_final_mark) { for (size_t i = 0; i < used_key_size; ++i) { create_field_ref(range.begin, i, index_left[i]); index_right[i] = POSITIVE_INFINITY; } } else { if (has_final_mark && range.end == marks_count) range.end -= 1; /// Remove final empty mark. It's useful only for primary key condition.
for (size_t i = 0; i < used_key_size; ++i) { create_field_ref(range.begin, i, index_left[i]); create_field_ref(range.end, i, index_right[i]); } } return key_condition.mayBeTrueInRange( used_key_size, index_left.data(), index_right.data(), primary_key.data_types); };
if (!key_condition.matchesExactContinuousRange()) {
while (!ranges_stack.empty()) //(2) { MarkRange range = ranges_stack.back(); ranges_stack.pop_back();
if (!may_be_true_in_range(range)) //(3) continue;
if (range.end == range.begin + 1) { /// We saw a useful gap between neighboring marks. Either add it to the last range, or start a new range. if (res.empty() || range.begin - res.back().end > min_marks_for_seek) //(4) res.push_back(range); else res.back().end = range.end; } else { /// Break the segment and put the result on the stack from right to left. size_t step = (range.end - range.begin - 1) / settings.merge_tree_coarse_index_granularity + 1; size_t end;
for (end = range.end; end > range.begin + step; end -= step) ranges_stack.emplace_back(end - step, end);
for (size_t i = 0; i < parts.size(); ++i) { PartInfo part_info{parts[i], per_part_sum_marks[i], i}; if (parts[i].data_part->isStoredOnDisk()) parts_per_disk[parts[i].data_part->volume->getDisk()->getName()].push_back(std::move(part_info)); else parts_per_disk[""].push_back(std::move(part_info)); }
for (auto & info : parts_per_disk) parts_queue.push(std::move(info.second)); }
// 遍历每一个线程,为每一个线程分配任务 for (size_t i = 0; i < threads && !parts_queue.empty(); ++i) { auto need_marks = min_marks_per_thread;
while (need_marks > 0 && !parts_queue.empty()) { auto & current_parts = parts_queue.front(); RangesInDataPart & part = current_parts.back().part; size_t & marks_in_part = current_parts.back().sum_marks; const auto part_idx = current_parts.back().part_idx;
/// Do not get too few rows from part. if (marks_in_part >= min_marks_for_concurrent_read && need_marks < min_marks_for_concurrent_read) need_marks = min_marks_for_concurrent_read;
/// Do not leave too few rows in part for next time. if (marks_in_part > need_marks && marks_in_part - need_marks < min_marks_for_concurrent_read) need_marks = marks_in_part;
/// Get whole part to read if it is small enough. if (marks_in_part <= need_marks) { ranges_to_get_from_part = part.ranges; marks_in_ranges = marks_in_part;
need_marks -= marks_in_part; current_parts.pop_back(); if (current_parts.empty()) parts_queue.pop(); } else { /// Loop through part ranges. while (need_marks > 0) { if (part.ranges.empty()) throw Exception("Unexpected end of ranges while spreading marks among threads", ErrorCodes::LOGICAL_ERROR);
... /// Do not leave too little rows in part for next time. // 如果此次获取到的range后,剩下的mark比较少,那么就一次行读整个DataPart,提高效率。 if (marks_in_part > need_marks && marks_in_part - need_marks < min_marks_to_read) need_marks = marks_in_part;
MarkRanges ranges_to_get_from_part;
/// Get whole part to read if it is small enough. //DataPart本身含有的mark总数就比较少,也一次性的读取整个DataPart if (marks_in_part <= need_marks) { const auto marks_to_get_from_range = marks_in_part; ranges_to_get_from_part = thread_task.ranges;
if (thread_tasks.sum_marks_in_parts.empty()) remaining_thread_tasks.erase(thread_idx); } else {
/// Loop through part ranges. // 遍历这个DataPart的range,找到足够数量的mark然后返回。 while (need_marks > 0 && !thread_task.ranges.empty()) { auto & range = thread_task.ranges.front();
SELECT StartURL AS URL, AVG(Duration) AS AvgDuration FROM tutorial.visits_v1 WHERE StartDate BETWEEN '2014-03-23' AND '2014-03-30' GROUP BY URL ORDER BY AvgDuration DESC LIMIT 10
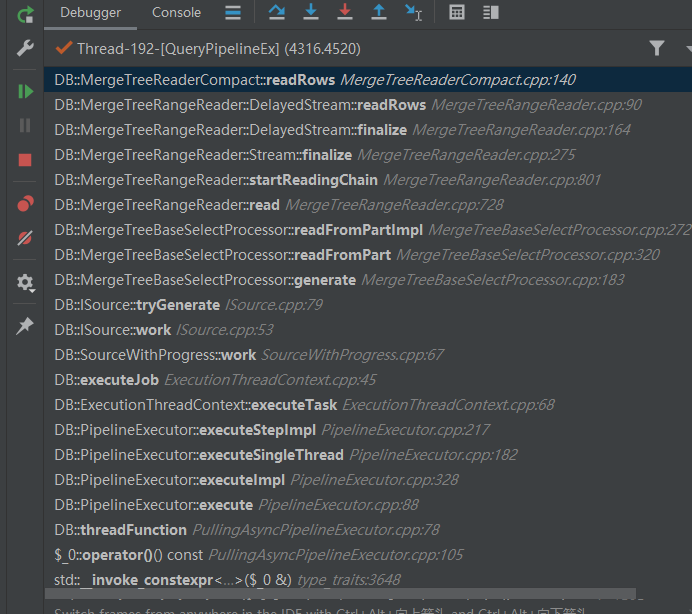
上述结果的 x 表示有几个这个类型的processor,比如有6个MergeTreeThread来拉取数据,而 x->y中,x表示有几个inPort,y表示有几个outPort。其中括号内的内容表示对应的queryPlanStep。笔者对ClickHouse中这一查询进行debug,其中具体pipeline表达如下图。相同颜色的表示同一类型的processor。
class IProcessor { protected: InputPorts inputs; OutputPorts outputs; public: virtual Status prepare() { throw Exception("Method 'prepare' is not implemented for " + getName() + " processor", ErrorCodes::NOT_IMPLEMENTED); }
/** Method 'prepare' is responsible for all cheap ("instantaneous": O(1) of data volume, no wait) calculations. * * It may access input and output ports, * indicate the need for work by another processor by returning NeedData or PortFull, * or indicate the absence of work by returning Finished or Unneeded, * it may pull data from input ports and push data to output ports. * * The method is not thread-safe and must be called from a single thread in one moment of time, * even for different connected processors. * * Instead of all long work (CPU calculations or waiting) it should just prepare all required data and return Ready or Async. * * Thread safety and parallel execution: * - no methods (prepare, work, schedule) of single object can be executed in parallel; * - method 'work' can be executed in parallel for different objects, even for connected processors; * - method 'prepare' cannot be executed in parallel even for different objects, * if they are connected (including indirectly) to each other by their ports; */ virtual Status prepare() { throw Exception("Method 'prepare' is not implemented for " + getName() + " processor", ErrorCodes::NOT_IMPLEMENTED); }
/// Optimization for prepare in case we know ports were updated. virtual Status prepare(const PortNumbers & /*updated_input_ports*/, const PortNumbers & /*updated_output_ports*/) { return prepare(); }
/** You may call this method if 'prepare' returned Ready. * This method cannot access any ports. It should use only data that was prepared by 'prepare' method. * * Method work can be executed in parallel for different processors. */ virtual void work() { throw Exception("Method 'work' is not implemented for " + getName() + " processor", ErrorCodes::NOT_IMPLEMENTED); } }
/// Edge represents connection between OutputPort and InputPort. /// For every connection, two edges are created: direct and backward (it is specified by backward flag). struct Edge { { update_info.update_list = update_list; update_info.id = this; }
/// Processor id this edge points to. /// It is processor with output_port for direct edge or processor with input_port for backward. bool backward; /// Port numbers. They are same for direct and backward edges. uint64_t input_port_number; uint64_t output_port_number;
/// Edge version is increased when port's state is changed (e.g. when data is pushed). See Port.h for details. /// To compare version with prev_version we can decide if neighbour processor need to be prepared. Port::UpdateInfo update_info; };
struct Node { /// Processor and it's position in graph. IProcessor * processor = nullptr; uint64_t processors_id = 0;
/// Direct edges are for output ports, back edges are for input ports. Edges direct_edges; Edges back_edges;
/// Ports which have changed their state since last processor->prepare() call. /// They changed when neighbour processors interact with connected ports. /// They will be used as arguments for next processor->prepare() (and will be cleaned after that). IProcessor::PortNumbers updated_input_ports; IProcessor::PortNumbers updated_output_ports;
/// Ports that have changed their state during last processor->prepare() call. /// We use this data to fill updated_input_ports and updated_output_ports for neighbour nodes. /// This containers are temporary, and used only after processor->prepare() is called. /// They could have been local variables, but we need persistent storage for Port::UpdateInfo. Port::UpdateInfo::UpdateList post_updated_input_ports; Port::UpdateInfo::UpdateList post_updated_output_ports;
using ThreadsData = std::vector<ThreadFromGlobalPool>; //(2) ThreadsData threads; threads.reserve(num_threads);
bool finished_flag = false; ...
if (num_threads > 1) { auto thread_group = CurrentThread::getGroup();
for (size_t i = 0; i < num_threads; ++i) { //(3)empalce_back函数接受的参数是lambda表达式会被转化为job。 threads.emplace_back([this, thread_group, thread_num = i] { /// ThreadStatus thread_status;
setThreadName("QueryPipelineEx");
if (thread_group) CurrentThread::attachTo(thread_group);
try { executeSingleThread(thread_num); //(4) } catch (...) { /// In case of exception from executor itself, stop other threads. finish(); tasks.getThreadContext(thread_num).setException(std::current_exception()); } }); }
/// Add childless processors to stack. uint64_t num_processors = nodes.size(); for (uint64_t proc = 0; proc < num_processors; ++proc) { if (nodes[proc]->direct_edges.empty()) { stack.push(proc); /// do not lock mutex, as this function is executed in single thread nodes[proc]->status = ExecutingGraph::ExecStatus::Preparing; } } ... while (!stack.empty()) { uint64_t proc = stack.top(); stack.pop(); updateNode(proc, queue, async_queue); ... } }
switch (node.last_processor_status) { case IProcessor::Status::NeedData: case IProcessor::Status::PortFull: { node.status = ExecutingGraph::ExecStatus::Idle; break; } case IProcessor::Status::Finished: { node.status = ExecutingGraph::ExecStatus::Finished; break; } case IProcessor::Status::Ready: { node.status = ExecutingGraph::ExecStatus::Executing; queue.push(&node);// node状态为ready表示该节点对应的processor,中的数据准备好了,可以进行处理, //放入queue里。当方法返回后,线程池中的线程会从这个队列里取出这个node然后执行其work方法。 break; } case IProcessor::Status::Async: { node.status = ExecutingGraph::ExecStatus::Executing; async_queue.push(&node); break; } case IProcessor::Status::ExpandPipeline: { need_expand_pipeline = true; break; } }
if (!need_expand_pipeline) {
for (auto it = node.post_updated_output_ports.rbegin(); it != node.post_updated_output_ports.rend(); ++it) { auto * edge = static_cast<ExecutingGraph::Edge *>(*it); updated_edges.push(edge); edge->update_info.trigger(); }
for (auto it = node.post_updated_input_ports.rbegin(); it != node.post_updated_input_ports.rend(); ++it) { auto * edge = static_cast<ExecutingGraph::Edge *>(*it); updated_edges.push(edge); edge->update_info.trigger(); }
auto & context = tasks.getThreadContext(thread_num); //(1) bool yield = false;
while (!tasks.isFinished() && !yield) { /// First, find any processor to execute. /// Just traverse graph and prepare any processor. while (!tasks.isFinished() && !context.hasTask()) tasks.tryGetTask(context); //(2)
while (context.hasTask() && !yield) { if (tasks.isFinished()) break;
/// ThreadPool with std::thread for threads. using FreeThreadPool = ThreadPoolImpl<std::thread>; class GlobalThreadPool : public FreeThreadPool, private boost::noncopyable
ReturnType ThreadPoolImpl<Thread>::scheduleImpl(Job job, int priority, std::optional<uint64_t> wait_microseconds) { .... /// Check if there are enough threads to process job. if (threads.size() < std::min(max_threads, scheduled_jobs + 1)) { try { threads.emplace_front(); } catch (...) { /// Most likely this is a std::bad_alloc exception return on_error("cannot allocate thread slot"); }
void ThreadPoolImpl<Thread>::worker(typename std::list<Thread>::iterator thread_it) { while (true) { /// This is inside the loop to also reset previous thread names set inside the jobs. setThreadName("ThreadPool");
if (!jobs.empty()) { /// boost::priority_queue does not provide interface for getting non-const reference to an element /// to prevent us from modifying its priority. We have to use const_cast to force move semantics on JobWithPriority::job. job = std::move(const_cast<Job &>(jobs.top().job)); jobs.pop(); } else { /// shutdown is true, simply finish the thread. return; }
}
if (!need_shutdown) { try { ... job(); // 执行真正的任务 /// job should be reset before decrementing scheduled_jobs to /// ensure that the Job destroyed before wait() returns. job = {}; } catch (...) { /// job should be reset before decrementing scheduled_jobs to /// ensure that the Job destroyed before wait() returns. job = {};
{ std::unique_lock lock(mutex); if (!first_exception) first_exception = std::current_exception(); // NOLINT if (shutdown_on_exception) shutdown = true; --scheduled_jobs; }
ClickHouse的线程实现为类ThreadFromGlobalPool,使用方法类似于std::thread,只不过添加了ThreadStatus for ClickHouse。ThreadFromGlobalPool的核心方法为他的构造函数。在创建ThreadFromGlobalPool对象时,同时也向GlobalThreadPool提交了job(方法scheduleorThrow中会调用上面讲到的scheduleImpl方法,从而将任务提交到线程池中去)
/// This moves are needed to destroy function and arguments before exit. /// It will guarantee that after ThreadFromGlobalPool::join all captured params are destroyed. auto function = std::move(func); auto arguments = std::move(args);
/// Thread status holds raw pointer on query context, thus it always must be destroyed /// before sending signal that permits to join this thread. DB::ThreadStatus thread_status; std::apply(function, arguments); });
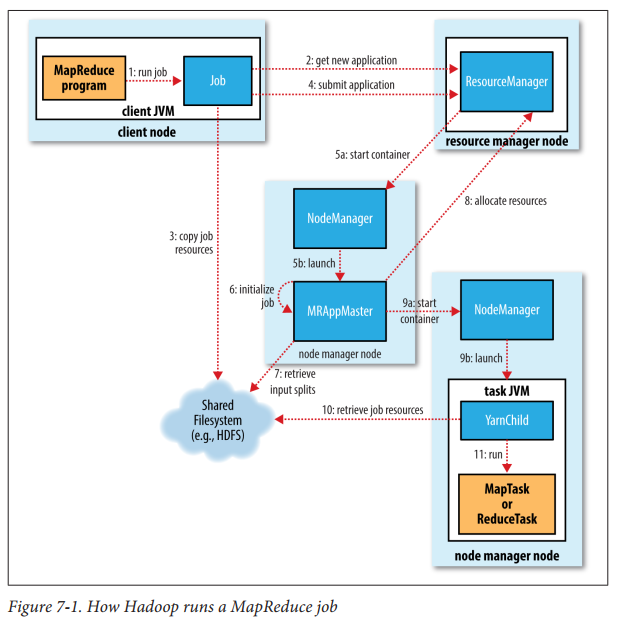
具体的Map-Reduce过程如下图所示。map将输入split处理后的结果写入磁盘等待reduce task 来拷贝,这里注意的是如果有多个reducer,那么每个map task的输出需要进行partion和sort操作(具体过程见Shuffle and Sort)。partion可以理解为对map的输出中的key进行划分,确保同一个key被分到同一个partion,而每个partion可以拥有多个key。每个partion对应于一个reducer,等全部map task完成后,对应partion的reducer会来取对应partion的数据。每个partion中的所有数据时根据key排序好的。途中表示的为三个mapper和2个reducer因此,每个mapper的输出被分为两个partion。具体的sort和partion过程,以及数据的存放形式见Shuffle and Sort。
shuffle and Sort
1 2 3
MapReduce makes the guarantee that the input to every reducer is sorted by key. The process by which the system performs the sort—and transfers the map outputs to the reducers as inputs—is known as the shuffle
[1]Zaharia, Matei, et al. “Resilient Distributed Datasets: A {Fault-Tolerant} Abstraction for {In-Memory} Cluster Computing.” 9th USENIX Symposium on Networked Systems Design and Implementation (NSDI 12). 2012.
[2]Zaharia, Matei, et al. “Spark: Cluster computing with working sets.” 2nd USENIX Workshop on Hot Topics in Cloud Computing (HotCloud 10). 2010.
[3]White, Tom. “Hadoop-The Definitive Guide: Storage and Analysis at Internet Scale. 4th.” (2015).